
When XML beats JSON: UI layouts
When demoing Hyperview to new engineers, there's one comment that frequently comes up about the HXML data format:
"XML, really? It's bloated and outdated. Why not use JSON? It's the future."
These comments imply that JSON is the "one true file format" that should be used for everything, but we don't believe there's such a thing. Each format makes tradeoffs in encoding, flexibility, and expressiveness to best suit a specific use case.
- A format optimized for size will use a binary encoding that won't be human-readable.
- A format optimized for extensibility will take longer to decode than a format designed for a narrow use case.
- A format designed for flat data (like CSV) will struggle to represent nested data.
In addition to the intrinsic properties of a format, external factors can influence its practical use cases, such as the popularity of the format among the target developers, or library support in the desired programming languages.
When choosing a file format to use in a software project, software engineers pick the one with the best balance of features and external factors for the situation. This post is the first in a 3-part series examining the decision process we used to choose XML over JSON as the format at the core of Hyperview. In part 1, we focus on the suitability of each format for defining user interfaces.
JSON for lists, XML for trees
Both XML and JSON can represent complex nested data structures, but they excel at different types of structures. JSON's origins as a subset of JavaScript can be seen with how easily it represents key/value object data. XML, on the other hand, optimizes for document tree structures, by cleanly separating node data (attributes) from child data (elements).
We can illustrate the advantages and disadvantages of each format by using both formats to represent two types of data: lists and trees.
Example 1: List of users
Let's represent a list of users. Each user has a first and last name, and a list of favorite movies. In JSON, there's a sensible way to model this data: as an array of objects with keys for the user properties:
[
{
"first_name": "Michael",
"last_name": "Scott",
"favorite_movies": [ "Diehard", "Threat Level Midnight" ]
},
{
"first_name": "Dwight",
"last_name": "Schrute",
"favorite_movies": [ "The Crow", "Wedding Crashers" ]
},
{
"first_name": "Pam",
"last_name": "Beesly",
"favorite_movies": [ "Legally Blonde" ]
}
]
A particular strength of JSON is its support for nested data structures. Notice that the list of movies can be easily represented using an array value for the favorite_movies key. In XML, however, element attributes must be strings. This means there's no officially supported way to represent the list of movies in an element attribute. We can hack this by encoding the list into an attribute using a comma delimiter:
<Users>
<User first="Michael" last="Scott" favoriteMovies="Diehard, Threat Level Midnight" />
<User first="Dwight" last="Schrute" favoriteMovies="The Crow, Wedding Crashers" />
<User first="Pam" last="Beesly" favoriteMovies="Legally Blonde" />
</Users>
This solution is not ideal. We're not using XML semantics to represent the list of movies, meaning we can't rely on XML syntax validation to verify the data. The clients reading the data will need to know how to split on commas and unescape the data in this particular attribtue. So both writing and reading the data is error-prone. To address these shortcomings, we should use XML syntax to represent the list of movies. This means creating child elements for each movie:
<Users>
<User first="Michael" last="Scott">
<Movie>Diehard</Movie>
<Movie>Threat Level Midnight</Movie>
</User>
<User first="Dwight" last="Schrute">
<Movie>The Crow</Movie>
<Movie>Wedding Crashers</Movie>
</User>
<User first="Pam" last="Beesly">
<Movie>Legally Blonde</Movie>
</User>
</Users>
With this approach, we avoid the hack of using a comma delimiter in an attribute. However, we've created another problem in the form of inconsistency: some user properties are represented as element attributes, others as child elements. The client has to know to look in both places to get all of the user's data. To be consistent, we can represent all user properties as child elements:
<Users>
<User>
<FirstName>Michael</FirstName>
<LastName>Scott</LastName>
<FavoriteMovies>
<Movie>Diehard</Movie>
<Movie>Threat Level Midnight</Movie>
</FavoriteMovies>
</User>
<User>
<FirstName>Dwight</FirstName>
<LastName>Schrute</LastName>
<FavoriteMovies>
<Movie>The Crow</Movie>
<Movie>Wedding Crashers</Movie>
</FavoriteMovies>
</User>
<User>
<FirstName>Pam</FirstName>
<LastName>Beesly</LastName>
<FavoriteMovies>
<Movie>Legally Blonde</Movie>
</FavoriteMovies>
</User>
</Users>
Now we have a consistent, extensible representation for a list of users in XML. But compared to the same data in JSON, this representation is overly verbose and hard to write. The XML syntax obscures the structure of the data.
So JSON is well-suited for representing lists of objects with complex properties. JSON's key/value object syntax makes it easy. By contrast, XML's attribute syntax only works for simple data types. Using child elements to represent complex properties can lead to inconsistencies or unnecessary verbosity.
Example 2: Org Chart
XML may not be ideal to represent generic data structures, but it excels at representing one particular structure: the tree. By separating node data (attributes) from parent/child relationships, the tree structure of the data shines through, and the code to process the data can be quite elegant.
A classic example of a tree structure is a company org chart. Let's assume each node in the tree is an employee, with a name and title. The edges in the tree represent a reporting relationship. The root of the tree is the boss.
In JSON, we represent each employee as an object with key/value pairs for the name and title. But JSON doesn't provide a separate notation for relationships vs attributes, so we must also use a key/value pair to represent an employee's direct reports:
{
"name": "Michael Scott",
"title": "Regional Manager",
"reports": [
{
"name": "Dwight Schrute",
"title": "Assistant to the Regional Manager"
},
{
"name": "Jim Halpert",
"title": "Head of Sales",
"reports": [
{
"name": "Andy Bernard",
"title": "Sales Rep"
},
{
"name": "Phyllis Lapin",
"title": "Sales Rep"
}
]
},
{
"name": "Pam Beesly",
"title": "Office Administrator"
}
]
}
Notice that it's hard to distinguish a node's properties from the relationships. It's common to prefix the relationship keys with "$" or "_" to make the distinction clearer, but this is a hack akin to using a delimiter in an XML attribute. When writing the JSON, we can cause errors by forgetting the prefix. Likewise when reading the JSON, we can't loop through the keys in an object without remembering to filter out the ones starting with the prefix. Both reading and writing the data is now error-prone and inelegant.
XML really shines when it comes to tree data: elements are nodes, attributes are node properties, and child elements imply the reporting relationship:
<Employee name="Michael Scott" title="Regional Manager">
<Employee name="Dwight Schrute" title="Assistant to the Regional Manager" />
<Employee name="Jim Halpert" title="Head of Sales">
<Employee name="Andy Bernard" title="Sales Rep" />
<Employee name="Phyllis Lapin" title="Sales Rep" />
</Employee>
<Employee name="Pam Beesly" title="Office Administrator" />
</Employee>
Compared to the JSON example, it's much easier to get a sense of the underlying structure of the data. Attributes of the employee (name and title) are cleanly separated from the employee relationships. The relationships are both easier to visualize when writing the file, and the code to read the data can operate on the overall structure without touching node properties. There's no chance of accidentally interpreting the relationship data as an employee attribute like in the JSON example.
The advantages of XML over JSON for trees becomes more pronounced when we introduce different node types. Assume we wanted to introduce departments into the org chart above. In XML, we can just use an element with a new tag name:
<Department name="Scranton Branch">
<Employee name="Michael Scott" title="Regional Manager">
<Department name="Sales">
<Employee name="Dwight Schrute" title="Assistant to the Regional Manager" />
<Employee name="Jim Halpert" title="Head of Sales">
<Employee name="Andy Bernard" title="Sales Rep" />
<Employee name="Phyllis Lapin" title="Sales Rep" />
</Employee>
</Department>
<Employee name="Pam Beesly" title="Office Administrator" />
</Employee>
</Department>
JSON doesn't have a concept of node types, so again we need to introduce a new special prefixed key to represent the type:
{
"$type": "department",
"name": "Scranton Branch",
{
"$type": "employee",
"name": "Michael Scott",
"title": "Regional Manager",
"$reports": [
{
"$type": "department",
"name": "Sales",
"$reports": {
"$type": "employee",
"name": "Dwight Schrute",
"title": "Assistant to the Regional Manager"
},
{
"$type": "employee",
"name": "Jim Halpert",
"title": "Head of Sales",
"$reports": [
{
"$type": "employee",
"name": "Andy Bernard",
"title": "Sales Rep"
},
{
"$type": "employee",
"name": "Phyllis Lapin",
"title": "Sales Rep"
}
]
},
},
{
"$type": "employee",
"name": "Pam Beesly",
"title": "Office Administrator"
}
]
}
}
Now it's JSON's turn to be bloated and hard-to-read. Meanwhile, the XML version represents the tree data succinctly without obscuring the underlying structure.
These two examples highlight the relative strengths and weaknesses of JSON and XML when representing different types of data:
- JSON excels at representing a collection of homogenous objects, where object properties can be composite data types
- XML excels at representing trees with heterogeneous objects, where object properties are simple data types
UI Layouts are trees
Hyperview's goal is to bring a web-like development experience to mobile:
- On the web, a server responds to an HTTP request with HTML/CSS to render a web page.
- In Hyperview, a server responds to an HTTP request with a response to render a mobile app screen.
In order to fill the role of HTML/CSS for mobile apps, Hyperview's file format must be able to define the layout and structure of an app screen's UI. And component trees are the best way to represent UI layouts. Every major UI framework out there uses a component tree. Xcode even offers an exploded 3D view that really highlights the underlying tree structure of a screen: each component has a parent component, and everything rolls up to a shared root component.
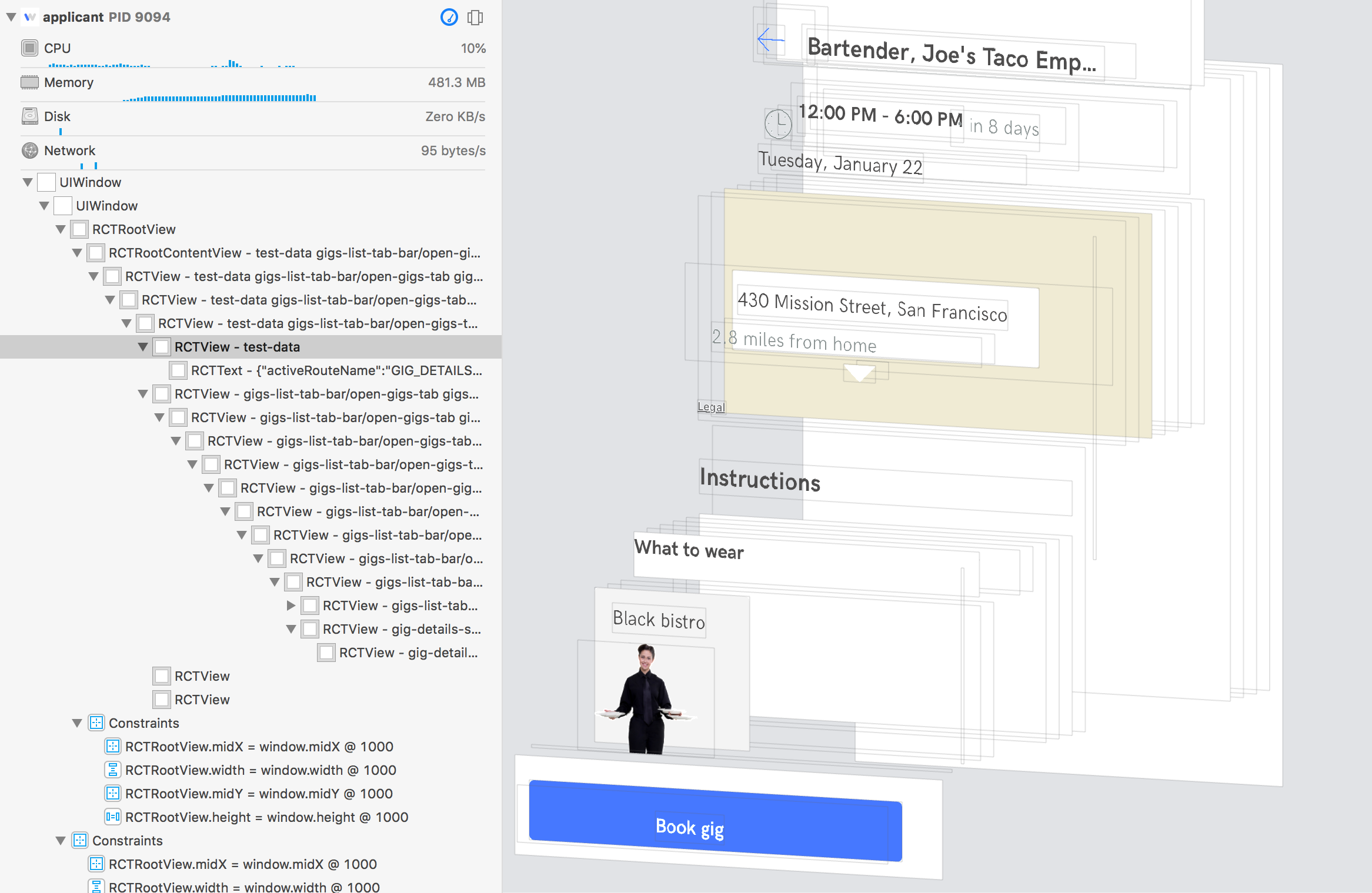
Trees are a powerful representation for UI layouts. They naturally provide component groupings, allowing designers and developers to use higher-level abstractions. When we need to hide, show, or animate a section of the screen, we don't need to change the state of each component in the section. Rather, we can change the state of the single parent component that contains every UI element of the section. When modifying a component, we only need to worry about what's in its subtree, and not what's happening at higher levels.
XML for UI Layouts
UI layouts are represented as component trees. And XML is ideal for representing tree structures. It's a match made in heaven! In fact, the most popular UI frameworks in the world (HTML and Android) use XML syntax to define layouts. Still not convinced? Take a look at React, the popular JS library designed around composing UI components. If there was ever a library to embrace JSON for defining UI, it should be React, right? But the React website actually recommends defining component UI using JSX, an XML-like format. Even though using JSX requires learning a new non-JS syntax and adding a transpiling step to the build process, the library authors feel it's worth the pain in order to use XML!
As noted at the beginning, each data format comes with certain tradeoffs. Overall, the benefits of XML for Hyperview outweigh the downsides, we still need to handle those rough spots. In particular, we noted that XML element attributes cannot natively represent lists of data. This case occurs in Hyperview with how we apply styles to elements. Due to this limitation of XML, styles are represented as space-separated ids, and the ids cannot contain spaces. Luckily, this limitation matches the behavior of the class attribute in HTML, so the approach is at least familiar to web developers.
Stay tuned for parts 2 and 3 of our exploration of XML and JSON in the context of Hyperview. Part 2 will cover the extensibility of JSON and XML, while Part 3 will compare the developer experience of both formats.